
Hadoop and Elasticsearch, Big Data
What is Big Data
Big Data is a technical term for data sets so large that traditional data processing methods such as relational databases or desktop statistics software are simply not adequate for its processing. Big Data may be of great value to you and your business. But why, you may ask. With the power of Big Data you will be able to better analyse and mine information from your data, or just store it in a convenient format for future use.
Big Data usually means
- Traditional enterprise data - such as customer profiles, ERP data and business transactions.
- Generated data and various measurements - e.g. data from industrial sensors, machine logs, GPS data etc.
- Social data - data from various social networks e.g. Facebook, Google+, Twitter, web analytics etc.
The most significant characteristic of Big Data is its sheer volume, but that is not the only one. You may also consider speed of data processing. For some tasks it is necessary to get instant results of computation with huge volume of streamed data. Next is variability of the data, structured documents as well as data with no inherent structure or multimedia streams. You may also consider the financial potential of information hidden in large sets of seemingly unrelated data. It is up to the Big Data approach to find this valuable information and put it to use.
Hadoop ecosystem
Hadoop is a complex system used to store extreme amounts of information using consumer-grade hardware (no need for a fancy enterprise storage systems). Various analyses and business reports can then be run on this data.
Hadoop has two main components:
- HDFS - a distributed filesystem.
- MapReduce - a module for distributed data processings.
See the image below for the system overview.
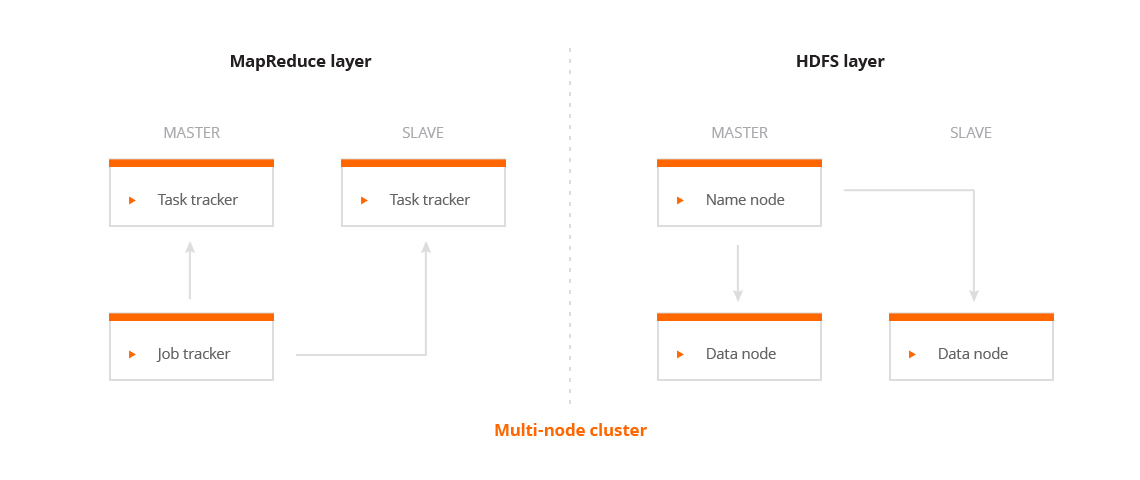
Next to these two basic components, Hadoop also includes the YARN module for orchestration of resources in a cluster. There is a multitude of systems based on Hadoop such as Mahout, HBase, Hive, Elasticsearch, Pig etc. Specific usage of these mutually complementary systems can be tailored to customer needs.
But why is Hadoop so important? The main reason is likely its ability to process huge amounts of data blazingly fast. Other reasons may include:
- Low cost - open source framework using consumer-grade hardware - no hidden expenses included.
- Computational performance - Hadoop's distributed computation model is able to process even more data than you may think (add more nodes for better performance).
- Scaling - start with a modest setup, go big later by adding nodes. As simple as it can be.
- Flexibility - there is no need to preprocess data as in a traditional relational database setup. Just store as much data as you want, leave the processing decisions for later.
- Data safety - all of your data is protected from hardware failure. Should one node fail, all its workload will be routed to the remaining nodes. All of the data is automatically replicated to other nodes (via replication factor).
Elasticsearch
Many of our clients experienced a simultaneous need for a Big Data solution and the ability to store and work with substantial amounts of semi-structured data. They required real-time operations such as full-text search, fuzzy search or decision-making based on this data. In these cases, we recommend the combination of Hadoop and Elasticsearch, which was developed exactly for this use case. The data is sent to Elasticsearch first and after being processed (or, if the clients requires it, at the same time) passed to the Hadoop cluster. The benefits of Hadoop also apply for Elasticsearch:
- Low cost - open source framework using consumer-grade hardware - no hidden expenses included.
- Computational performance - Elasticsearch's distributed computation model is able to process even more data than you may think (add more nodes for better performance).
- Scaling - start with modest setup, go big later by adding nodes. As simple as it can be.
- Flexibility - there is no need to preprocess data as in a traditional relational database setup. Just store as much data as you want, decide on the processing later.
- Data safety - all of your data is protected from hardware failure. Should one node fail, all its workload will be routed to the remaining nodes. All of the data is automatically replicated to other nodes (via replication factor).
Data analysis
Let's assume we want to store a considerable amount of data to our Hadoop (or Hadoop + Elasticsearch) cluster. What can we do with this data? The answer is quite simple - we can create complex analyses and reports, observe a "live" data stream, make real-time decisions based on data in the cluster (application logs and such) and much more.
These analyses allow you to clearly see potential in your business, better target your advertising, utilize feedback from your clients, categorize data, and much more. This can be a substantial gain for just a small initial investment. Furthermore, you can cut expenses due to automation of processes. With Big Data and Mule ESB you can fully automate all the possible processes!
Our solution
We offer a quality service of professionals in the fields of Big Data and data analysis, installation and maintenance of the whole platform as well as training for your personnel. Naturally, our solution to your requests is going to be tailored. There is simply no other way in this area. The reason is that each customer has different business requirements and different needs for processed data. Many of the components are generic and reusable, so the development is never from scratch. Some of our clients process online data from Elasticsearch cluster (millions of records) and send SMS, others store all information on their customers (including data from social networks gathered by Mule ESB) in their cluster. Some of our clients "only" gather application logs and evaluate them. As you can see, our portfolio is quite diverse. With us you are not limited in any way. We will turn your ideas and needs into a real solution.
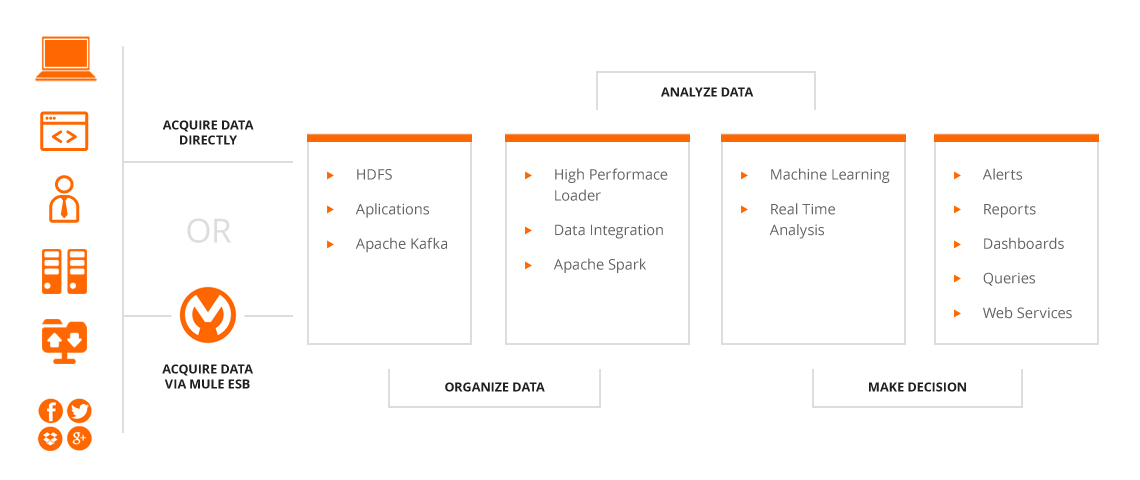
Our Big Data solution is based on Hadoop cluster (or Hadoop + Elasticsearch if needed) and powerful distributed computational systems, which provide you a fast access to your data. Quite often we see simultaneous requsts for Big Data solution, System Integration using Mule ESB and user and roles integration with Keycloak SSO. This way the data can flow straight to the Hadoop and Elasticsearch clusters for further processing.
Some of our projects briefly
- Big Data deployments - numerous production deployments of Hadoop, Elastic and OrientDB (loosely coupled with data grid systems like Infinispan).
- BI Reporting Tool - modern business reporting tool on huge data stored on Hadoop cluster.
- Big Data loader - smart Big Data loader tool for Hadoop platform.
- Business Analysis Tool - tool for gathering useful information about your business by using various statistical methods.